Kubernetes Lab
| Last Edited | |
|---|---|
| Tags | |
| study |
I found a quick course pretty interesting, named “Fault-Tolerant Web Hosting on Kubernetes”. The course introduces pod expansion and ingress controllers in Kubernetes. The expansion of pods increases the fault tolerance of a web application, and the ingress controller distributes network traffic.
I spent one hour finishing the course, but I feel I am missing something. Scaling up and down web services is another important feature of a large-scale deployment. When requests for visiting a web service are high, the pods increase their number and vise-visa. At the end of the day, I set up the goal of my extended study, which is to deploy a web service with an autoscaling feature.
Horizonal Pod AutoScaling
Full document: Horizontal Pod Autoscaling https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
Horizontal Pod Autoscaling means loading more pods or fewer pods,
whereas vertical pod scaling means updating more resources in a pod.
“The HorizontalPodAutoscaler is implemented as a Kubernetes API resource and a controller. The resource determines the behavior of the controller. The horizontal pod autoscaling controller, running within the Kubernetes control plane, periodically adjusts the desired scale of its target (for example, a Deployment) to match observed metrics such as average CPU utilization, average memory utilization, or any other custom metric you specify.”
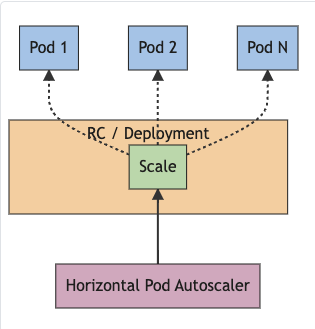
Kubernetes Horizontal Autoscaler
Full tutorial: HorizontalPodAutoscaler Walkthrough https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
Here are a few steps I recorded.
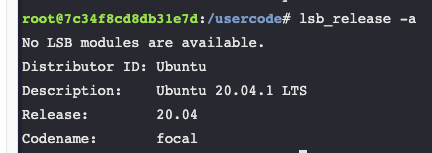
- System version check. I used one project space in educative.io
The system version is Ubuntu 20.04.1
- create a multi-node cluster & metrics server
# three node (two workers) cluster config
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: workerkind create cluster --name multi-node --config=multi-node.yaml
kubectl get nodes

kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
- Create pods and autoscaler for the application
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apachekubectl apply -f php-apache.yaml
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
# Increase load
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
kubectl get hpa --watch
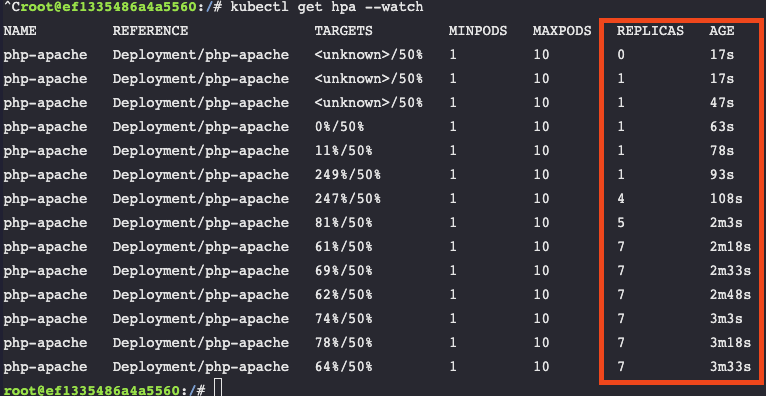
Notice the pods increase from 0 to 7 as the load increases.
More Tutorials:
NGINX Tutorial: Reduce Kubernetes Latency with Autoscaling https://www.nginx.com/blog/microservices-march-reduce-kubernetes-latency-with-autoscaling/
https://itnext.io/autoscaling-ingress-controllers-in-kubernetes-c64b47088485